Some time ago I had to download some large files from the website, of one of the ransomware groups, in order to analyze the published (stolen) data. The leak was huge, hundreds of gigabytes, split in many large files and all published on the website hosted in Tor network.
The Tor network for anonymous communication and information exchange is ideal, but, for example, downloading files, torrents and other heavy materials is inefficient due to the speed of the network itself. Its not designed to exchange huge files, and that what Tor project developers is saying since the beginning.
With the development of the Tor project, the speed and capabilities have increased and, for example, watching YouTube videos or downloading smaller files is possible and relatively fast compared to the early days many years ago.
Also not all files you are downloading using Tor Browser have a chance to resume download in case of lost connection or new circuit or identity change.
If you visit http://ransomwr3tsydeii4q43vazm7wofla5ujdajquitomtd47cxjtfgwyyd.onion/ you can see list of active ransomware group sites. Before ransomware start encryption of files, they are all exfiltrated to the ransomware operator server, all data in attacked company is encrypted and negotiation for encryption key starts. Each of group publish leaked data, if ransom is not paid.
Sometimes companies don’t know what exactly was leaked, and sometimes they don’t pay the ransom and download their unencrypted data after the leak :) but every time, you need to analyze what was leaked and limit further dangers of publishing company data.
So I had a task to download leak, analyze it, assess the risk and suggest what other attacks and threats may arise from the disclosed data. Overall, it’s a boring analytical task, but I was able to automate the process of downloading large files from the Tor network.
Ahh, before I describe technical details, one more challenge is managers…
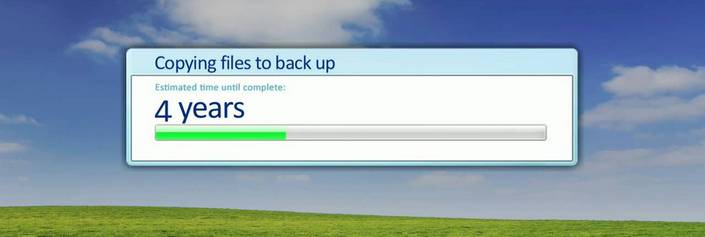
I like the surprise on the faces of managers who ask how long it will take to download 300 giga of leaked data from Tor, and I say, with luck about 20 weeks. Then the conversation starts: “no way”, “that it has to be ASAP”, “best answer is to have it for yesterday”, “tomorrow at the latest”, “in the worst case by the end of the week during business hours” etc. So you need to start explain non technical guys how Tor network works :| Sometimes there are even ideas that if our computer is too slow or our network is weak, they can pay for the best connection and the fastest computer just to have the data for tomorrow (maybe you should have paid the ransom you would have data very fast back on drives, or invested in security before this sad situation occurred). Nobody understand that 300 GB of data with average speed of 0,2 MBit/s will take exactly 200000 minutes, so 138,9 days or 19,84 weeks or 4,563 months. The way of presenting stats depends on how stressed out the manager is and his sense of humor. Never mind.
Introduction
Ok, to sum up steps from technical part, because it’s friday and I made it a little chaotic.
Solution, checks every one hour if curl is downloading files over Tor from the list of provided files, and all stuff is done in the background session. If download is dead, it will start it again, files on the list are rotated and resume on errors. Thanks to that you can forgot about it and wait till all files will be saved on local disk. You can remove logging errors and statuses option from the scripts, I did it because I was testing also other solutions for notifications. In general it’s not perfect, but it works. You can from time to time login to the virtual machine and check if everything works, like check network traffic or active sessions sudo screen -ls and if you want see how curl works bring back session sudo screen -r <ID>. To leave session press Ctrl-A and d to detach the screen. That’s all, maybe it will be useful for someone.
I assume that you have knowledge of Linux and it basic commands.
Technical part
Curl, screen and Tor is all you need. Install virtual machine with Debian (no GUI needed, just minimal version of Debian, or whatever distribution you like, but in my example it’s Debian, configure it with your user and sudo stuff etc).
Install curl, screen and tor:
1 | sudo apt install curl tor screen psmisc |
Create a folder where files will be downloaded, put there text file with all links you want to download, one file per line.
Tor configuration is minimal (sudo nano /etc/tor/torrc)
1 | RunAsDaemon 1 |
Restart it:
1 | sudo service tor restart |
In your home user directory create file curl.sh and put there:
1 |
|
change /home/user/test/download/ to location of your download folder and change urls.txt to the file you created that contains URLs to files. This file if executed will start download files listed in text file, one by one and retry on failure.
In details, xargs build and execute command lines from standard input, in our case it take each line from txt file and pass it to curl. -x parameter is for proxy and we are using socks5 for Tor. So far we have curl over Tor with list of files to download -L. Then -O is for remote name, so each downloaded file will be saved on disk with the same name as file on server. -k for insecure connection, by default, every SSL connection curl makes is verified to be secure, we don’t need that for Tor connection. --retry will retry number of times before giving up. --retry-max-time limit the total time allowed for retries and finally -C - tell curl to automatically find out where/how to resume the transfer. It then uses the given output/input files to figure that out.
Then create another file called checker.sh and put there:
1 |
|
This script will check if process with xarg in name is running. If running, it will add log entry Running - no action - <date of check>" to the log file var/log/download.log If not running then entry about failure will be added to the same log file, then dead screen session in the background will be killed, this will be also added as note to the log file and new session will be created where our curl script for download files is executed.
Be careful as the log file can grow and eat up all your disk space, if you don’t need the logging option push everything to dev null \> /dev/null
Last thing is to add checker.sh script to the crontab.
1 | sudo crontab -e |
then add:
1 | 0 * * * * /home/user/checker.sh |
to execute script every hour.
When all done execute command:
1 | sudo sh checker.sh |
It will check if the curl screen is running and create a fresh, first one, then cron will run it for you again every hour and create a new one if the curl download is interrupt.
Enjoy downloading big files from Tor.
List preparation
Some time ago, I had to download not only large files, but a huge list of small and medium files from ransomware leak. It is always about creating a proper file with URLs. Each URL must be on a separate line, no spaces or other weird characters.
You can also use sed to add quotes at the beginning and end to make sure that each line is a single URL.
1 | sed 's/.*/"&"/' input.txt > output.txt |
This tool is great for manipulating and preparing link list.
In addition, ransomware groups started sharing leaked files as a list of files rather than large archives, as they realised that each large leak is almost impossible to download over Tor or takes too much time, so leaked files are locked and leaking them is not harmful to victims. So they make files available as loose files and directories, where each can be accessed from the browser. In most cases, these are some kind of freely available libraries for listing files on a website like a jsTree or similar. Then you just have to list the files or get their names and build a list of URLs.
Each site may be different, the important thing is to find a starting point and build a list of files from there.
In my case, I was able to download a file with a directory listing.
1 | .: |
So all I had to do was clean it up and, using a Pythion script I invented using ChatGPT, format it to give me a full list of URLS to pass to curl.
1 | import re |
I was able to format the source list by searching only for file and directory names (regex magic in Python) and then add my URL to each file, so I had URL with onion domain, folder and filename. Which I used again in curl.
I will eventually learn Python, but I also wanted to show that you can use AI if you lack the know-how or if you want to automate something. Instead of manually modifying a file with different regexes.